

Estimacion de factores comunes en multiples series de tiempo
Conferencista: Maria E. Correal N.
Ph. D. en Estadística, Universidad Nacional de Colombia, Sede Bogotá
Profesora Asociada
Facultad de Ingeniería - Universidad de los Andes
Fecha: Lunes 06 de octubre de 2014
Lugar: Bloque 43-110
Hora: 10:00 a.m
Descargar resumen
La ley de Benford aplicada en detección de fraude de datos
Fechas: 15 de septiembre de 2014
Titulo Mini-Curso: Distintos enfoques de análisis de datos en Ciencias Físicas
Fechas: 16, 17 y 18 de septiembre de 2014
Expositor: Alex E. Kossovsky, M. Sc. City University of New York
Descragar conferencia.pdf
Descargar mini-curso.pdf
Term structure of implied risk neutral densities
Conferencista: Enrique ter Horst
Ph. D en Estadística, Duke University
Docente Colegio de Estudios Superiores de Administración, CESA. Bogotá
Fecha: Lunes 05 de mayo 2014
Diseños óptimos secuenciales de discriminación
Conferencista: Svetlana I. Rudnykh
Magíster Estadística Aplicada
Estudiante Doctorado en Ciencias-Estadística
Fecha: Lunes 07 de abril 2014
Weak dependence with apllication to subsample extremes
Conferencista: Paul Doukhan, Ph. D
Profesor Cergy-Pontoise University, France
Fecha: Lunes 03 de marzo 2014
A Robust Algorithm for Template Estimation Based on Manifold Embedding
Conferencista: Santiago Gallón
Docente de planta
Departamento de Matemáticas y Estadística
Facultad de Ciencias Económicas
Universidad de Antioquia
Fecha: Lunes 24 de febrero 2014
Derivados en Tasas de Interés
Conferencista: César Augusto Gómez Vélez
Docente Escuela de Estadística
Universidad Nacional de Colombia, Sede Medellín
Fecha: Lunes 21 de octubre 2013
Modelos de Regresión Beta Mixtos
Conferencista: Olga Cecilia Usuga Manco
Docente Escuela de Estadística.
Universidad Nacional de Colombia, Sede Medellín
Fecha: Lunes 23 de septiembre 2013
Descargar pdf
Optimización de procesos de recolección y muestreo mediante el uso de las TICs: Captura de encuestas con dispositivos móviles
Conferencista: Nilton Edu Montoya Gómez
Estadístico informático
Especialista en gestión de información y bases de datos
Estudiante Maestría en Ingeniería de Software
Profesor Facultad Nacional de Salud Pública de la Universidad de Antioquia.
Fecha: Lunes 9 de septiembre 2013
Video presentación parte I
Video presentación parte II
Tiempos de Primer Arribo y Probabilidades de Escape. Aplicaciones en Riesgo de Crédito y Pensiones
Conferencista: Norman Giraldo Gómez
Docente Escuela de Estadística.
Universidad Nacional de Colombia, Sede Medellín
Fecha: Lunes 26 de agosto 2013
Análisis de la Distribución Beta 2 Escalada como Distribución A Priori para los Parámetros de Varianza en Modelos de Jerárquicos Bayesianos
Conferencista: Isabel Ramírez Guevara
Ph.D (c). Docente Escuela de Estadística.
Universidad Nacional de Colombia, Sede Medellín
Fecha: Lunes 20 de mayo 2013
Diagnósticos para el Modelo GSK
Conferencista: Juan Carlos Correa Morales
Ph.D. en Estadística. Docente Escuela de Estadística.
Universidad Nacional de Colombia, Sede Medellín
Fecha: Lunes 29 de abril 2013
Descargar pdf
La Modelación del Precio Mensual de la Electricidad en Colombia: Elementos Economótricos
Conferencista: Elkin Castaño Vélez
M. Sc. en Estadística, Universidad Nacional de Colombia,
Docente de la Escuela de Estadística
Universidad Nacional de Colombia, Sede Medellín
Fecha: Lunes 8 de abril 2013
Optimización Bayesiana de Portafolios
Conferencista: Alejandro Regino Gómez
M. Sc en Estadística, Universidad Nacional de Colombia
Gerente de Modelos Cuantitativos
Dirección de Productos Especiales
Valores Bancolombia S.A. Comisionista de Bolsa
Fecha: Lunes 25 de febrero 2013
El Análisis Fractal como Elemento en la Modelación Estadística
Conferencista: Gabriel Conde A.
Profesor Escuela de Estadísitca
Universidad del Valle, Cali
Fecha: Lunes 11 de febrero 2013
Variabilidad Espacial del Suelo
Conferencista: Daniel F. Jaramillo J.
Profesor Titular y Maestro Universitario
Escuela de Geociencias
Facultad de Ciencias
Universidad Nacional de Colombia, Sede Medellín
Fecha: Lunes 19 de noviembre 2012
Modelos de Efectos Mixtos en Imágenes de Resonancia Magnética para el Estudio de la Interacción de la Enfermedad de Alzheimer y el Envejecimiento
Conferencista: Juan David Ospina
M. Sc. en Estadística
Ph. D (c) en Estadística
Escuela de Estadística
Grupo de Investigación en Estadística, Escuela de Estadística, Universidad Nacional de Colombia, Medellín
Fecha: Lunes 29 de octubre 2012
Analysis of the elicited prior distributions using tools of functional data analysis
Conferencista: Carlos Javier Barrera Causil
M. Sc. en Estadística
Ph. D (c) en Estadística
Escuela de Estadística
Grupo de Investigación en Estadística, Escuela de Estadística, Universidad Nacional de Colombia, Medellín
Fecha: Lunes 22 de octubre 2012
Descargar pdf
Aplicaciones prá¡cticas de métodos estadísticos al análisis de riesgos en el mercado financiero
Conferencistas: Juan David Urrego Moreno
Gerencia de Estructuración y Derivados
Vicepresidencia de Mercado de Capitales
Bancolombia S.A
Juan Sebastiá¡n Cardona Pineda
Gerente de Estructuración y Derivados
Vicepresidencia de Mercado de Capitales
Bancolombia S.A
Fecha: Lunes 24 de septiembre 2012
Descargar pdf
Reforma Regulatoria y cambios de control corporativo en la industria energética en Europa
Conferencista: Jhon J. García
Departamento de Economía
Universidad Eafit
Fecha: Lunes 10 de septiembre 2012
Descargar pdf
Aproximación Estadística para Reducir malware dentro de un sistema de información bancario
Conferencista: Gustavo Valencia. M. Sc (c) en Estadística
Escuela de Estadística
Universidad Nacional de Colombia
Fecha: Lunes 27 de agosto 2012
Changing the paradigm how to test statistical hypothesis
Conferencista: Luis R. Pericchi, Ph.D.
Profesor Adjunto Escuela de Estadística
Professor of Department of Mathematics and Center for Biostatistics and Bioinformatics,
University of Puerto Rico, Rio Piedras, San Juan, PR
Fecha: Lunes 13 de agosto 2012
Indicadores básicos antropomátricos, cómo es la cosa?
Conferencista: Jesés Antonio Camacho
Antropológo
Fecha: Lunes 25 de junio 2012
Etapas clínicas y progresión de la enferemedad de Alzheimer Familiar Mutación E280A en presenilina 1. Cohorte Antioquia E280A 1995-2010
Conferencista: Natalia Acosta Baena
Grupo de Neurociencias de Antioquia. Facultad de Medicina. Universidad de Antioquia
Fecha: Lunes 04 de junio 2012
Algunos Límites de Escala de Grafos Aleatorios en R2
Conferencista: Alexander Valencia
Doctor. Instituto de Matemáticas y Estadística de la Universidad Sao Paulo, Brasil
Fecha: Lunes 28 de mayo 2012
Predicción de los precios de la energía en la bolsa de Colombia para los próximos 10 años utilizando modelos de cambio de régimen
Conferencista: Jovan Cano
Candidato a doctor en Ingeniería. Universidad Nacional de Colombia
Fecha: Lunes 7 de mayo 2012
Raíz unitaria en presencia de múltiples cambios de nivel. El caso de la serie mensual de precios de la electricidad en Colombia.
Conferencista: Elkin Castaño Vélez
Profesor Asociado. Escuela de Estadística. Universidad Nacional de Colombia
Fecha: Lunes 23 de abril 2012
Análisis de supervivencia en presencia de riesgos que compiten
Conferencista: Fabián Jaimes B
Profesor Asociado, Departamento de Medicina Interna, Universidad de Antioquia
Fecha: Lunes 26 de marzo 2012
Una Introducción a las Pruebas de Raíces Unitarias Estacionales con Aplicaciones en R
Conferencista: Julio César Alonso
Director Centro de Investigaciones en Economía y Finanzas. Director Académico Maestría en Economía de la Universidad ICESI
Fecha: Lunes 12 de marzo 2012
En esta conferencia se presenta una introducción al problema de raíces unitarias estacionales. Es común encontrar discusiones acerca de las implicaciones de la presencia de raíces unitarias en las series, sin embargo, recientemente ha cobrado importancia el estudio de las raíces unitarias estacionales en los datos de frecuencia trimestral o mensual. Se identificarí los distintos tipos de raíces unitarias estacionales, la aplicación de la prueba HEGY para su identificación y la manera de solucionar el problema mediante una adecuada diferenciación de las series. También explicaremos paso a paso como realizar estos procedimientos en el software estadístico R.
Descargar pdf
Para ampliar información por favor consultar las siguiente páginas:
http://ideas.repec.org/p/col/000131/009098.html
http://www.icesi.edu.co/jcalonso/images/medellin2012/codigorparademostracion%20.txt
Avances en Modelos Predictivos en Radioterapia
Conferencista: Juan David Ospina
M.Sc en Estadística. Candidato a Doctor en Estaística, Universidad Nacional de Colombia, Sede Medellín y University de Rennes 1
Fecha: Lunes 13 de febrero 2012
Con el fin de minimizar los efectos secundarios de la radioterapia en el tratamiento del cáncer de próstata se han propuesto diferentes modelos que permiten estimar las probabilidades de que dichos eventos se presenten. Utilizando estas herramientas se puede ajustar el tratamiento de manera que se minimicen las probabilidades de reaparición del cáncer y al mismo tiempo de presentar efectos secundarios desagradables. En esta conferencia se presentan brevemente algunos modelos clásicos y su estimación, para pasar luego a nuevas propuestas que utilizan bosques aleatorios (random forest), análisis en componentes principales y modelos no paramétricos de efectos mixtos.
Small area estimation
Conferencista: Nicholas T. Longford
SNTL and Universitat Pompeu Fabra, Barcelona, Spain
Fecha: Diciembre 5 de 2011
National population surveys are important sources of information about the economic, educational, social, political and health-care issues in a country. Some users of such surveys are interested not only in the nation-level summaries, but also in their versions for smaller administrative units, such as regions and districts (small areas). The surveys usually have sample sizes sufficient for inferences about the country as a whole, but not about every district.
Small-area statistics comprises a collection of methods for inferences about small administrative units based on national surveys. Its key statistical techniques are related to borrowing strength across the districts, by means of empirical Bayes models in which the districts are associated with similar (related) regressions. The seminar will review these methods, discuss its problematic features, outline some adaptations and give some examples.
Basic references:J.N.K. Rao (2003). Small Area Estimation. Wiley, New York.
N.T. Longford (2005). Missing Data and Small-Area Estimation.
Springer-Verlag, New York.
Un método basado en remuestreo para la construcción de bandas de confianza
Conferencista: Carlos Mario Lopera Gómez
Candidato a Doctor. Universidad Nacional de Colombia, Sede Medellín. Docente Escuela de Estadística. Universidad Nacional de Colombia, Sede Medellín
Fecha: Noviembre 28 de 2011
En muchos modelos estadísticos es posible utilizar una lista apropiada de los valores observados (reales, vectoriales o incluso funcionales) para obtener aproximaciones asintóticamente exactas de las distribuciones de las desviaciones de los estimadores a los parámetros de interés. Con este fin se usan muestras aleatorias con reemplazo, a partir de las cuales se pueden aproximar tales distribuciones, cuando n tiende a infinito. El soporte teórico de este método se basa en una extensión de la convergencia débil, que usa análogos estadísticos del Teorema de Límite Central para procesos estocásticos. La aproximación sugerida puede servir de base para la implementación de bandas de confianza para un parámetro o función de interés. En este trabajo, se ilustra el método anterior para la construcción de bandas de confianza en la estimación no paramétrica de la función de distribución acumulada.
Palabras clave: Aproximación débil, Bootstrap, Estimador no paramétrico, Remuestreo, Teorema de límite central de remuestreo.
Descargar pdf
Diseños óptimos para estimación y discriminación en modelos no lineales de efectos mixtos
Conferencista: María Eugenia Castañeda
Candidata a Doctora. Universidad Nacional de Colombia, Sede Medellín. Profesora Instituto de Matemáticas. Universidad de Antioquia
Fecha: Noviembre 21 de 2011
El problema de construir diseños experimentales óptimos para la estimación eficiente de los parámetros poblacionales en modelos no lineales de efectos mixtos, ha sido considerado y desarrollado ampliamente bajo diferentes enfoques, principalmente, derivación de diseños D-óptimos y diseños óptimos Bayesianos. En el caso de diseños óptimos, y de algunos criterios que maximizan funcionales de la matriz de información, expansiones de Taylor de primer y segundo orden del modelo alrededor de los parámetros aleatorios son utilizadas con frecuencia para la derivación de éstos diseños.
En algunos estudios de aplicación, los diseños óptimos con múltiples objetivos como estimación eficiente de los parámetros y discriminación entre modelos competitivos, simultáneamente, pueden ser más eficientes que aquellos diseños que se derivan con un fin específico. Generalmente, estos diseños se obtienen mediante la composición de los criterios de optimalidad de interés y se llaman óptimos compuestos. De acuerdo a la exploración bibliográfica realizada hasta el momento, muy pocos trabajos han abordado el problema de diseños óptimos compuestos para modelos no lineales de efectos mixtos.
Específicamente, en el caso de estimación y discriminación, algunos autores han sugerido el uso del criterio óptimo producto. Los diseños que se obtienen bajo este criterio pueden calcularse fácilmente pero no son tan eficientes para discriminar en algunos casos. El objetivo de esta charla es presentar una introducción a los diseños óptimos en modelos no lineales de efectos mixtos para estimación de parámetros y discriminación entre dos modelos. Además de sugerir una metodología para la construcción de diseños óptimos con estos dos objetivos a partir de la composición de los criterios de D-optimalidad y T-optimalidad.
Monitoreo de perfiles
Conferencista: José A. Vargas N.
Departamento de Estadística. Universidad Nacional de Colombia, Sede Bogotá
Fecha: Octubre 24 de 2011
Con el fin de minimizar los efectos secundarios de la radioterapia en el tratamiento del cáncer de próstata se han propuesto diferentes modelos que permiten estimar las probabilidades de que dichos eventos se presenten. Utilizando estas herramientas se puede ajustar el tratamiento de manera que se minimicen las probabilidades de reaparición del cáncer y al mismo tiempo de presentar efectos secundarios desagradables. En esta conferencia se presentan brevemente algunos modelos clásicos y su estimación, para pasar luego a nuevas propuestas que utilizan bosques aleatorios (random forest), análisis en componentes principales y modelos no paramétricos de efectos mixtos.
Descargar pdf
Técnicas de Imágenes Médicas
Conferencista: Thomas M. Deserno
Head of Division Medical Image Processing, Universidad de Aachen, Alemania
Fecha: Octubre 10 de 2011
Se presentará una introducción a las diferentes técnicas médicas. Se tratarán los siguientes temas: Mejoramiento de imágenes, historia de las imagenología médica, composición y procesamiento de imágenes, ejemplos, estadísticas asociadas a la definición de una imagen, histogramas, estructura de la imagen, variedad y variabilidad. Adicionalmente se hablarí de incertidumbre, exactitud y el concepto de robustez.
Descargar pdf
Stationary and Spatial Unit Roots in Regional Data
Conferencista: Andrés Ramírez H.
Candidato a Doctor en Ciencias Estadística
Fecha: Septiembre 26 de 2011
Stationarity is an implicit assumption in statistical inference when data come from a random field, but this hypothesis has to be checked in order to avoid falling in nonsense regressions and inconsistent estimates. In this presentation, consequences on statistical inference associated with non-stationary random fields are shown, specifically due to a spatial unit root. Two statistical tests to check a spatial unit root in regional data are built, and their asymptotic distributions and limiting sizes are found. Monte Carlo simulations are used to obtain the small sample properties of the proposed statistical tests, and it is found that the size of the tests are good, and the power of the tests improve if the spatial autocorrelation coefficient decreases. In order to get better small sample properties of the tests when there is a spatial unit root near to one, Monte Carlo tests are performed. Finally, two applications are done.
Descargar pdf
Cuando Encuestar es la última Salida
Conferencista: Wilson Guillermo García.
Especialista en Sistemas de Información
Fecha: Septiembre 12 de 2011
El ideal del análisis de datos es contar con una base de datos unificada y bien depurada, la cual provenga de un sistema de registro organizado y continuo, sin embargo, en las organizaciones de todo tipo siempre se encuentran dificultades en contar con datos e información sobre algunos temas estratégicos, y es por esto es que se recurre frecuentemente a procesos de levantamiento de información en campo o la aplicación de encuestas. Cuando nos vemos enfrentados a la necesidad de encuestar para obtener información relevante para la toma de decisiones y la acción, es importante revisar algunas consideraciones de índole técnica a fin de mantener el control del proceso y asegurar los resultados. En este sentido es de vital importancia, realizar un buen diseño del operativo de campo, especificar unos criterios de calidad de los datos, realizar un control de los equipos de encuestaje y actuar prontamente en la solución de los inconvenientes que surgen en el proceso.
Enfoque Bayesiano en la Obtención de Tasas de Transición
Conferencista: René Iral Palomino. Candidato a Doctor.
Fecha: Agosto 22 de 2011
Resumen
Los métodos de estimación bayesianos han probado ser útiles en situaciones de alta complejidad, especialmente cuando se usan técnicas Monte Carlo Markov Chain (Gordon, 2001). Por otra parte los modelos de estados múltiples han mostrado ser muy útiles para el análisis de datos longitudinales, particularmente aquellos que involucran información acerca de la progresión de una enfermedad a través del tiempo (Salazar et al, 2007). Trabajos previos en esta dirección han reportado dificultades de tipo computacional en el proceso de obtención de las tasas de transición de un estado a otro (Salazar et al, 2007, Kay, 1986). En este trabajo se comparan dos métodos Bayesianos para la obtención de las tasas de transición que gobiernan un modelo de tres estados con estructura markoviana de primer orden: Uno basado en la discretización del rango parametral y otro basado en el muestreador de Gibbs. Estas tasas de transición se vinculan con las covariables por medio de un modelo del tipo Andersen-Gill (1993). Estas dos técnicas bayesianas se comparan vía simulación con la técnica de estimación estudiada por Iral y Salazar (2007).
Methods for planning repeated measures degradation studies
Conferencista: Luis A. Escobar. Ph.D.
Fecha: Agosto 01 de 2011
Resumen
Análisis de Tablas de Contingencia Vía GSK
Conferencista: Juan Carlos Correa Ph.D.
Fecha: Mayo 30 de 2011
Resumen
El análisis de datos cualitativos es un área de importancia en el trabajo aplicado. El modelo lineal clásico ha sido utilizado extensivamente y con mucho éxito en múltiples situaciones. En 1969 Grizzle, Srtarmer y Koch presentaron una metodología, conocida como GSK, que es lo suficientemente flexible y poderosa para aplicarse a multitud de situaciones en el manejo de tablas categóricas multidimensionales.
Descargar pdf
Haciendo Visible lo Invisible: Uso de Métodos Estadísticos no Paramétricos y Dimensionales en Estudios de Ecología de Microorganismos del Suelo
Conferencista: Juan Carlos Pérez. Ph.D.
Fecha: Mayo 16 de 2011
Resumen
Varias herramientas estadísticas, microbiológicas y moleculares han ayudado a entender la importancia de los microorganismos para el mantenimiento de la vida en nuestro planeta. Sin embargo, esas herramientas también sugieren que el mundo de los microorganismos del suelo continúa siendo casi inexplorado.
Esta presentación ilustra el uso del escalado multidimensional para visualizar grupos de secuencias de ADN, y de modelos de rarefacción (saturación de especies) para estimar biodiversidad de microorganismos a partir de muestreos parciales. Como ejemplo se incluyen investigaciones con dos grupos de microorganismos del suelo que son benéficos para las plantas en ecosistemas terrestres: los hongos micorrizales y las rizobacterias.
Los resultados del análisis por escalado multidimensional y rarefacción permitieron visualizar en estos microorganismos varios patrones de diversificación y adaptación en el suelo, que de otra forma pasarían desapercibidos. Por ejemplo, el escalado multidimensional indicó la separación espacial de diferentes hongos de micorriza en una misma raíz, y los análisis de rarefacción permitieron detectar puntos del suelo que son mas apropiados para la búsqueda de bacterias benéficas a las plantas. Se sugiere que la implementación de éstas y otras herramientas estadísticas aceleraría el desarrollo de bioproductos y tecnologías basadas en el uso de microorganismos del suelo.
Modelos y Análisis para Datos de Degradación en Confiabilidad Industrial
Conferencista: Sergio Yáñez Canal. Candidato a Doctor
Fecha: Abril 11 de 2011
Resumen
La degradación es un deterioro progresivo que eventualmente puede causar la falla (e.g., el desgaste que sufren los neumáticos de un automóvil). Cuando es posible medirla, esta puede proporcionar mayor información que los datos de tiempo de falla, para propósitos de determinación y mejoramiento de la confiabilidad de un producto. Esta conferencia es de carácter divulgativo y desarrolla técnicas que son propuestas por Meeker y Escobar (1998). Se cree importante hacer conocer este tópico, hoy en la frontera de la Teoría de Confiabilidad (Lawless (2000); Hong, Meeker y Escobar (2009)). En este trabajo se compara el análisis aproximado de degradación con el modelo de degradación explícito. Estos últimos modelos implican la utilización de modelos físicos de degradación a los cuales se les introduce efectos aleatorios. Se implementan las técnicas para la estimación de modelos mixtos en S-Plus siguiendo a Pinheiro y Bates (2000) y se utiliza el bootstrap para intervalos de confianza.
Palabras claves: Teoría de Confiabilidad, Datos de Degradación, Bootstrap, Modelos de Efectos Mixtos, Efectos Aleatorios.
Modelos Lineales Mixtos con Estructura de Covarianza Espacial y Temporal en los Errores
Conferencista: Mercedes Andrade Bejarano. Ph.D
Fecha: Marzo 28 de 2011
Resumen
En datos de temperatura promedio mensual colectados en Valle del Cauca, Colombia, en 28 estaciones meteorológicas, durante el período 1971 a 2002, se identifican dos fuentes de variación: 1) Debido a aspectos temporales, como la tendencia a incrementar valores de temperatura en series de tiempo para algunos sitios, la variación estacional debida a los dos períodos secos en la zona Andina (Enero-Febrero, Julio-Agosto) y los dos períodos húmedos (Abril-Mayo, Octubre-Noviembre) y los fenómenos del Niño y la Niña, asociados con aumentos y disminuciones, respectivamente, en los valores de temperatura
promedio. La otra fuente de variación es debida a aspectos espaciales, la temperatura cambia con la altitud, tendiendo a ser más baja cuando la altitud incrementa y los sitios cercanos tienden a tener valores similares de temperatura promedio que
sitios alejados espacialmente. Estas fuentes de variabilidad motivaron la escogencia de modelos lineales mixtos (Henderson, 1982) con estructura de covarianza espacial y temporal de los errores, en los cuales años y sitios están asociados con efectos aleatorios y la altitud y los indicadores para los fenómenos de la Niña y el Niño están asociados con efectos fijos. Outliers en los modelos lineales mixtos ajustados, son analizados a través de un estudio de simulación.
Transformación de Box-Cox no Paramétrica y Robusta para el Modelo de Regresión
Conferencista: Elkin Castaño Vélez
Fecha: Marzo 14 de 2011
Resumen
Frecuentemente en el análisis de regresión es necesario transformar la variable dependiente con el fin de obtener aditividad, errores normales y varianza constante. Box y Cox (1964) proponen una transformación paramétrica de potencia basada en la normalidad del término de error, con el propósito de lograr dichos objetivos. Sin embargo, algunos autores tales como Carroll (1980, 1982 b), Bickel and Doksum (1981), Powell (1991), Marazzi y Yohai (2003) han señalado que dicha transformación no es robusta cuando existen observaciones atípicas en la muestra y proponen estimadores robustos para el parámetro de transformación reemplazando la verosimilitud normal con una función objetivo que es menos sensible a observaciones atípicas.
En esta conferencia se presenta un procedimiento alternativo no paramétrico y robusto que permite obtener la transformación de potencia en la familia de transformaciones de Box y Cox cuando existen observaciones atípicas en la variable dependiente. El procedimiento es una extensión de la propuesta de Castaño (1994, 1995, 1996) para una transformación de simetría de un conjunto de datos.
Seminario de Procesos Estocásticos
Independencia Condicionada. Propiedades de Invarianza
Conferencista: Miguel Ángel Marmolejo Lasprilla
Fecha: Febrero 28 de 2011
Resumen
Una Nota sobre el Requisito de Rentabilidad Mínima de los Fondos de Pensiones Obligatorias en Colombia
Conferencista: Norman D. Giraldo Gómez
Fecha: Febrero 14 de 2011
Resumen
En este trabajo se introduce un modelo para el flujo de caja de los saldos de una cuenta de pensiones obligatorias invertida en un fondo en el cual la tasa de rendimiento presenta movimientos extremos, para examinar la hipótesis que en un período de tiempo cualquiera se disminuya el saldo de la cuenta por efecto de rendimientos negativos y, sin embargo, se cumplan los requisitos exigidos sobre rentabilidad mínima. La garantía de rendimiento
mínimo consiste en mantener el promedio móvil de los rendimientos mensuales durante 36 meses corridos por encima de un mínimo, establecido por ley y reportado de manera periódica. El modelo propuesto es un proceso autorregresivo gaussiano de orden p, con p alto y raíces del polinomio autorregresivo muy cerca del cículo unitario, y un ruido superpuesto a este proceso, modelado como una sucesión iid distribuída Normal Inversa Gaussiana (NIG), para incluir colas pesadas en el proceso.
Robust Statistical Modeling Using the Birnbaum-Saunders-t
Distribution with Applications
Conferencista: Víctor Leiva
Fecha: Noviembre 29 de 2010
Resumen
The Student-t model belongs to a class of distributions called normals scale mixture. This class has appealing properties such as robust estimates, easy number generation, and efficient computation of the ML estimates via the EM-algorithm; see Dempster et al. (1977), Lange et al. (1989) and Lucas (1997). The Birnbaum-Saunders (BS) model is a two-parameter, unimodal, positively skewed distribution that is related to the normal model and has received considerable attention in the last decades; see Johnson et al. (1995), Leiva et al. (2009) and Balakrishnan et al. (2009).
In this talk, robust modeling using the Birnbaum-Saunders-t distribution is presented. Specifically, preliminary aspects related to BS and log-BS distributions and their generalization from the Student-t distribution are introduced. Then, BS-t regression models including maximum likelihood estimation based on the EM algorithm and influence diagnostic tools are discussed. Finally, the introduced and discussed results are applied to real data using the R package, which shows the utility of the proposed model.
Keywords: EM algorithm; Generalized Birnbaum-Saunders distribution; Influence diagnostics; Likelihood methods; Log-linear models; Robustness; Sinh-normal distribution.
Aplicaciones Estadísticas a Heurísticas Evolutivas
Conferencista: Juan David Ospina Arango
Fecha: Noviembre 8 de 2010
Resumen
La computación evolutiva ha venido llamando la atención en ciencias e ingenierías por su capacidad de responder de manera adecuada en situaciones donde los métodos de optimización tradicionales no son aplicables. En esta charla se introduce brevemente los algoritmos denominados "evolutivos" y se presentan algunas aplicaciones en el área estadística. Se presenta el MAGO (Multi Dynamics Algorithm for Global Optimization), una heurística desarrollada en la Universidad Nacional de Colombia - Sede Medellín, y se muestra cómo conceptos de uso frecuente en estadística y probabilidad pueden usarse para la creación de técnicas heurística.
Análisis de Datos Genómicos Heterogéneos
Conferencista: Liliana López Kleine
Fecha: Octubre 25 de 2010
Resumen
A pesar de la existencia de una gran cantidad de datos genómicos, el papel preciso de muchas proteínas no ha sido elucidado. Para avanzar en el conocimiento de la función de proteínas, haciendo uso de los datos genómicos disponibles en las bases de datos, ha surgido la Biología de Sistemas, que busca extraer conocimiento a partir del análisis global de diferentes tipos de datos haciendo uso de herramientas estadísticas adecuadas.
Se ilustrarán las etapas de un estudio de Biología de Sistemas con base en un ejemplo específico de determinación del papel de proteínas de función desconocida haciendo uso de un análisis de correlación canónica basado en kernels. El ejemplo permitirá hacer énfasis en las dificultades que surgen en el análisis y la interpretación de datos genómicos, los cuales están relacionados principalmente con su heterogeneidad y altas dimensiones.
Igualmente, se mostrará la aplicabilidad de los métodos kernel a otro tipo de estudios de análisis de datos genómicos.
Préstamos de Valores
Conferencista: César Augusto Gómez Vélez
Fecha: Octubre 11 de 2010
Resumen
Se presenta un modelo para préstamos en condiciones de mercado incompleto y se hace uso de la teoría de control estocástico para valorar un tipo de préstamos en los que una acción cuyo precio varía aleatoriamente en el tiempo es dejada como garantía del préstamo pudiendo ser recuperada a cualquier momento hasta un vencimiento fijado en el contrato.
El problema consiste en calcular los parámetros del modelo que hagan justa esta transacción, en particular el valor del servicio de préstamo y la tasa de intereses sobre éste, considerando el valor inicial y la dinámica de la acción.
Statistical Properties of the Quantile Normalization Method to Curve Alignment and a New Procedure Based on the Dynamic Time Warping Algorithm
Conferencista: Santiago Gallón
Fecha: Septiembre 20 de 2010
Resumen
Sometimes the underlying outcome of a statistical process instead to be a random variable is a sample of curves which may have amplitude or phase variations or both simultaneously. To obtain a common pattern that represents the structural average behavior diverse curve alignment methods have been proposed. Among these, the quantile normalization method by Bolstad et al. [3] has the advantages to be simple and quick with respect to others. However its statistical properties has not been derived yet. In this paper we prove the large sample properties of this method and, additionally, propose a new curve alignment procedure applying the dynamic time warping algorithm on the normalized spacings associated to the sample data in order to improve one drawback of the quantile normalization method.
Keywords: Order statistics; Spacings; Quantile normalization; Estructural expectation; Curve registration; Dynamic time warping algorithm
SISB N III: Aplicación de Métodos Estadísticos para la Focalización de Población Pobre en Colombia
Conferencista: Martha Ligia Restrepo Zea
Fecha: Septiembre 13 de 2010
Resumen
El Sisbén es un instrumento de focalización individual que identifica los hogares, las familias o los individuos más pobres y vulnerables. Es un sistema de información colombiano que permite identificar a la población pobre potencial beneficiaria de programas sociales. El Sisbén está conformado por tres elementos: La ficha de clasificación socioeconómica –Encuesta-, el software con el que se estiman los puntajes del índice y el índice Sisbén. En esta conferencia se darán: Las razones para cambiar el índice SISBÉN; los principales problemas del índice Sisbén II, las soluciones ofrecidas por el Sisbén III y el marco conceptual de este índice.
Spatial Unit Root Process in Regional Data Some Consequences
Conferencista: Andrés Ramírez Hassan
Fecha: Agosto 30 de 2010
Resumen
Stationarity is an implicit assumption in statistical inference when data comes from random process or random fields, but this hypothesis has to be checked through formal or informal analysis in order to avoid falling in nonsense regressions and inconsistent estimated parameters. We are going to present some simulation exercises in order to show some consequences because of spatial unit root process.
Conferencia 1: Desarrollo de nuevos marcadores biológicos para la enfermedad de Alzheimer: Estimación del espesor cortical a partir de imágenes de resonancia magnética (MRI).
Conferencia 2: Nuevos desafíos en procesamiento de imágenes médicas para radioterapia de próstata.
Conferencista: Óscar Acosta Tamayo
Fecha: Agosto 17 y 18 de 2010
Resumen
El objetivo de la investigación en análisis de Imágenes Biomédicas es el desarrollo de nuevos métodos y herramientas computacionales, no sólo para la caracterización de enfermedades a partir de las imágenes, sino también para el entrenamiento, la planificación y la ayuda a la terapia.
Proyectos en curso en todo el mundo cubren una gran variedad de modalidades (Resonancia Magnética MRI, Tomografía por emisión de Positrones PET, Tomografía por rayos X CT, Ultrasonido, etc) y buscan fusionar información anatómica, funcional y molecular.
Algunos métodos integran dentro de los algoritmos el conocimiento del experto sobre la fisiología, la biología, la patología y la física de la adquisición de la imagen.
Descargar Conferencia 1.pdf
Descargar Conferencia 2.pdf
Un Modelo Estocástico para la Descripción del Proceso de Envejecimiento Celular
Conferencista: Liliana Blanco Castañeda
Fecha: Mayo 24 de 2010
Resumen
Hay dos tipos de teorías que buscan explicar el proceso de envejecimiento: las determinísticas y las estocásticas. La primeras afirman que el proceso de envejecimiento está predeterminado, esto es, el envejecimiento es la continuación del proceso de desarrollo de los seres vivos y corresponde a la última etapa dentro de una secuencia de eventos codificados en el genoma. Las teorías estocásticas, por su parte, afirman que el proceso de envejecimiento es consecuencia de una serie de alteraciones que ocurren de manera aleatoria y que se acumulan a lo largo del tiempo.
En esta charla presentaremos un modelo estocástico de umbral para describir el proceso de envejecimiento basado en la teoría del desgaste, según la cual cada organismo está compuesto de partes irremplazables y la acumulación del daño en sus partes vitales llevaría a la muerte de las células, tejidos, órganos y finalmente del organismo. La capacidad de reparación del ADN (esta es una macromolécula que forma parte de todas las células y que contiene información genética usada en el desarrollo y funcionamiento de los tejidos vivos) se correlaciona positivamente con la longevidad de las diferentes especies. Cuando la acumulación total de daño genético alcanza un cierto nivel de umbral, que va más allá de la capacidad de reparación de la célula, ésta muere.
Los estados en que se puede encontrar una célula serán descritos de acuerdo al número de daños genéticos que ésta ha sufrido. Se calcularán la probabilidad de que la célula se encuentre en los diferentes estados, para cada instante de tiempo, y el número esperado de reparaciones que ella ha
sufrido en un intervalo de tiempo arbitrario.
Inference for Mutually Exclusive Competing Events through a Mixture of Generalized Gamma Distributions
Conferencista: Alvaro Muñoz Villegas
Fecha: Mayo 12 de 2010
Resumen
Time- to- event data with two or more types of endpoints are found in many epidemiologic settings. Instead of treating the times for one of the endpoints as censored observations for the other, we present an alternative approach where we treat competing events as distinct outcomes in a mixture. Our objective was to determine if and how the mixture was modified in response to an intervention.
We used a mixture of generalized gamma distributions to concatenate the overall frequency and distribution of the times of two competing events commonly observed in critical care trials, namely unassisted breathing followed by hospital discharge alive and in-hospital death. We applied our proposed methods to data from two randomized clinical trials of critically ill patients.
Mechanical ventilation with lower tidal volumes modified the mixture (p=0.103) when compared with traditional tidal volumes by lowering the overall frequency of death (p=0.005), rather than through affecting either the distributions of times to unassisted breathing (p=0.477) or times to death (p=0.718). Likewise, use of a conservative versus a liberal fluid management modified the mixture (p<0.001) by achieving earlier times to unassisted breathing (p<0.001) and not through affecting the overall frequency of death (p=0.202) or the distributions of times to death (p=0.693).
La Metodología Estadística Aplicada en el Colombiano
Conferencista: Gilma Salinas Villada
Fecha: Abril 26 de 2010
Resumen
En esta conferencia se pretende dar un recuento histórico del grupo de investigación del Colombiano, se presentarán las etapas de un proceso de investigación típica realizada en el Colombiano, además se mostrarán ejemplos de los trabajos realizados por esta institución. Se hablará acerca de cómo se define el tema a investigar, la forma como se determina el diseño del muestreo, definición de la población objetivo, tamaño muestral y el margen de error. También se comentará acerca de las dificultades que se dan típicamente en los diferentes estudios y los análisis que comúnmente se realizan después de obtener los datos, entre otros tópicos.
Análisis de Inequidades: Uso de la Curva y el Ãndice de Concentración
Conferencista: Jorge Martínez Collantes
Fecha: Abril 12 de 2010
Resumen
Esta charla pretende dar a conocer una herramienta estadística de gran utilidad para el análisis de la relación entre dos variables haciendo énfasis en las diferencias que se puedan presentar en diferentes intervalos de la variable independiente Este procedimiento tiene especial aplicación en el estudios de inequidades en salud y educación, pudiendo ser adaptado a investigaciones en otras áreas.
¿ Otra Vez el Teorema de Bayes ?
Conferencista: Olga Lucía Zapata Cárdenas
Fecha: Marzo 15 de 2010
Resumen
En este seminario se presentará una experiencia exitosa en la enseñanza del teorema de Bayes. Se revisarán algunos aspectos epistemológicos relacionados con las dificultades que presentan los estudiantes en la comprensión del teorema y se concluirá con algunas sugerencias para la enseñanza.
Pronóstico y Estructuras de Volatilidad Multi-Período de la Tasa de Cambio del Peso Colombiano
Conferencista: Elkin Castaño Vélez
Fecha: Marzo 8 de 2010
Resumen
Debido a la naturaleza heterocedástica de los retornos de la tasa de cambio, la modelación de su proceso de volatilidad es de gran importancia en la toma de decisiones macroeconómicas y del mercado financiero. Para modelar la dinámica de dicho proceso, se han propuesto diversos modelos estadísticos, entre de los cuales la metodología ARCH ha jugado un papel preponderante. Estudios recientes han encontrado evidencia sobre la persistencia en el proceso de media y/o en la volatilidad en los retornos de la tasa de cambio de varios países.
Para modelar estas dinámicas algunos autores han empleado modelos ARFIMA para detectar y estimar la existencia de memoria larga en el proceso de media y modelos IGARCH, FIGARCH, HYGARCH y HYAPARCH para estimar el proceso de volatilidad. El objetivo de este trabajo es buscar evidencia sobre una especificación adecuada para el proceso de media y de volatilidad de la tasa de cambio del Peso colombiano con respecto al Dólar americano durante el período comprendido entre enero de 2000 y julio de 2006. Con base en el modelo obtenido se calcula la volatilidad multi-período y la estructura a plazos.
Se utiliza la estrategia de modelos anidados, donde se inicia con el modelo ARFIMA-HYAPARCH como el modelo más general en el cual se admite la existencia de los hechos estilizados encontrados en las series financieras.
AlRededores: usando R en entornos colaborativos
Conferencista: Carlos J. Gil Bellosta
Fecha: Febrero 12 de 2010
Resumen
En esta charla es considerado el problema de la modelación y estimación de los costos de garantía descontados durante un período de garantía fijado, para un sistema coherente reparado mínimamente a nivel de sus componentes y es propuesto un estimador puntual y los respectivos intervalos de confianza para el costo de garantía esperado para un período fijado.
Palabras Claves: Componentes críticos, Reparo mínimo, semimartingala regular, sistema coherente, teorema de límite central martingalas.
Estimación de Costos de Garantía por Reparos Mínimos en Sistemas Coherentes Bajo el Modelo de Tiempo de Vida General
Conferencista: Nelfi G. González Álvarez
Fecha: Febrero 8 de 2010
Resumen
En esta charla es considerado el problema de la modelación y estimación de los costos de garantía descontados durante un período de garantía fijado, para un sistema coherente reparado mínimamente a nivel de sus componentes y es propuesto un estimador puntual y los respectivos intervalos de confianza para el costo de garantía esperado para un período fijado.
Palabras Claves: Componentes críticos, Reparo mínimo, semimartingala regular, sistema coherente, teorema de límite central martingalas.
La Integral de Riemann-Stieltjes como Integral con Respecto a una Medida
Conferencista: Pedro Isaza Jaramillo
Fecha: Diciembre 14 de 2009
Resumen
En esta charla se revisarán algunos aspectos de la teoría de integración que pueden ser estudiados por medio de la teoría de la medida y para los cuales la teoría de la integral de Riemann-Stieltjes resulta insuficiente. Algunos de estos aspectos son: Los teoremas de intercambio de límite con integral, el teorema fundamental del cálculo, la noción de densidad, la regla de Leibniz de diferenciación de la integral con respecto a un parámetro
Descargar pdf
Ajuste de un Modelo de Regresión Weibull conCensura de Intervalo
Conferencista: Mario César Jaramillo Elorza
Fecha: Noviembre 23 de 2009
Resumen
El análisis de supervivencia trata de la evaluación estadística de variables que miden el tiempo hasta un evento de interés. En el área de estudios clínicos y epidemiológicos, este evento es muchas veces el inicio de una enfermedad, la desaparición de los síntomas de una enfermedad o la muerte. Una particularidad del análisis de supervivencia es la utilización de datos censurados. En esta conferencia se presenta una alternativa para modelar el tiempo de supervivencia, con censura de intervalo, cuando dicho tiempo esta altamente correlacionado con otra variable que se mide en algunos tiempos específicos.
Para implementar dicho análisis se utilizó una base de datos que incluye información demográfica, genética y clínica relacionada con artritis reumatoide y que fue recopilada por investigadores de la Corporación para Investigaciones Biológicas CIB. La severidad de la enfermedad para cada persona se valoró de acuerdo al puntaje de Sharp-van-der Heijde. La variable respuesta del modelo de regresión Weibull es la edad del paciente en la cual se adquiere un daño sustancial en las articulaciones, que es alcanzado cuando el paciente obtiene un puntaje de erosión mayor o igual a 5.
Esta estrategia de modelamiento permitió, en este caso particular, revelar factores importantes que influencian el daño temprano y que sugieren diferentes mecanismos patológicos que afectan el daño en las articulaciones de manos y pies, además nos sugiere que cuando se tenga una variable que esté muy asociada con el tiempo de supervivencia, que se encuentra censurado en intervalo, lo mas conveniente es usar esta variable para imputar el tiempo de supervivencia verdadero.
Palabras Clave: Modelo de regresión Weibull, Análisis de Supervivencia, Genética, Artritis Reumatoide, Verosimilitud, Censura de Intervalo.
Descargar pdf
Geostatistical Analysis of Functional Data
Conferencista: Ramón Giraldo Henao
Fecha: Octubre 19 de 2009
Resumen
Functional data analysis concerns with statistical modelling of random variables taking values in a space of functions (functional variables). Several standard statistical techniques such as regression, ANOVA or principal components, among others, have been considered from a functional point of view. In general, these methodologies are focused on independent and identically distributed functional variables. However, in several disciplines of applied sciences there exists an increasing interest in modeling of spatially correlated functional data is of interest. This is the topic treated here. Specifically this work concerns with spatial prediction of curves when we dispose of a sample of curves collected at sites of a region with spatial continuity.
Four methods for doing spatial prediction of functional data are developed. Initially, we propose a predictor having the same form as the classical kriging predictor, but considering curves instead of one-dimensional data. The other predictors arise from adaptions of functional linear models for functional response to the case of spatially correlated functional dat. One the one hand, we define a predictor which is a combination of kriging and the functional linear point-wise (concurrent) model. On the other hand, we use the functional linear total model for extending two classical multivariate geostatistical methods to the functional context. The first predictor is defined in terms of scalar parmeters. In the remaining cases the predictors involves functional parameters involved in the predictors proposed. In all cases a non-parametric approach based on expansion in terms of basis functions is used for getting curves from discrete data.
Intervalos de confianza para Cpk de distribuciones Weibull
Conferencista: Isabel Cristina Ramírez Guevara
Fecha: Octubre 5 de 2009
Resumen
Los índices de capacidad de proceso se utilizan para determinar si un proceso puede cumplir con las especificaciones. Para estudiar la capacidad de un proceso se asume que el proceso está en estado de control estadístico y que la distribución del proceso es normal.
En este estudio se calculan intervalos de confianza para el índice de capacidad Cpk cuando la característica de interés sigue una distribución Weibull. Para estimar los parámetros de la distribución se asume que se tiene una muestra aleatoria de un proceso estable. Basándose en esta muestra, se usan dos metodologías para estimar los parámetros de la distribución, regresión simple en el papel de probabilidad Weibull y estimadores de máxima verosimilitud. Con estos parámetros, se estima la media y la varianza y con éstos el valor del índice de capacidad del proceso. Para obtener intervalos de confianza, se usa el método ¨bootstrap¨. Finalmente, se analiza la longitud, el nivel de confianza obtenido y el sesgo de la estimación de los intervalos de confianza obtenidos.
Un Modelo de Regresión Weibull para Datos sobre Proyección de Artritis Reumatoide
Conferencista: Juan Carlos Salazar Uribe
Fecha: Septiembre 21 de 2009
Resumen
En la investigación médica, especialmente en la relacionada con enfermedades complejas, encontrar evidencias de asociación de factores con el tiempo que transcurre hasta que una persona experimenta un daño sustancial ocasionado por una enfermedad es de fundamental importancia. Es esta conferencia se presenta un análisis de supervivencia de la edad a la que una persona experimenta un daño importante en las articulaciones de pies y manos usando un modelo de regresión Weibull. Para implementar dicho análisis se utilizó una base de datos que incluye información demográfica, genética y clínica relacionada con artritis reumatoide y que fue recopilada por investigadores de la Corporación para Investigaciones Biológicas CIB.
La severidad de la enfermedad para cada persona se valoró de acuerdo al puntaje de Sharp-van-der Heijde, el cual se usó posteriormente para clasificar el daño en las articulaciones en tres categorías: Leve, Moderado y Severo. Estos puntajes se asignaron a partir de evidencia radiológica la cual fue analizada de manera independiente por dos especialistas en radiología. El grado de acuerdo entre las lecturas hechas por los especialistas se evaluó usando el coeficiente de correlación intraclase (ICC). Esta estrategia de modelamiento permitió, en este caso particular, revelar factores importantes que influencian el daño temprano y que sugieren diferentes mecanismos patológicos que afectan el daño en las articulaciones.
Palabras Clave: Modelo de regresión Weibull, Análisis de Supervivencia, Radiografía, Genética, Artritis Reumatoide
Apreciación de Gráficos Estadísticos
Conferencista: Juan Carlos Correa Morales
Fecha: Septiembre 7 de 2009
Resumen
La comunicación mediante gráficos que representan información cuantitativa es una tarea corriente entre los usuarios de métodos estadísticos. Es desafortunado que esta área de la estadística no tenga el mismo nivel de interés y desarrollo que otras áreas. En esta presentación realizamos un recorrido histórico del desarrollo de los métodos gráficos y comentamos el trabajo en investigación que se ha realizado.
Cuantificación óptima de Sistemas Multivariantes Mixtos
Conferencista: Guillermo Correa Londoño
Fecha: Agosto 24 de 2009
Resumen
Se presenta un sistema de cuantificación óptima de sistemas multivariantes mixtos, basado en la minimización de la suma de las interdistancias cuadráticas entre las categorías cuantificadas de las diferentes variables. Esta condición garantiza que las categorías más frecuentemente asociadas reciban cuantificaciones más similares. Al no estar basado en la reducción de la dimensionalidad, este sistema, denominado Cuantifica, genera cuantificaciones únicas, a diferencia de las generadas mediante las técnicas del sistema Gifi de análisis multivariante no lineal. En adición a los niveles de escalamiento clásicos (Numérico, Ordinal y Nominal), Cuantifica soporta niveles de Escalamiento Numérico Flotante y Ordinal Flotante, los cuales permiten manejar categorías del tipo “No sabe/No responde”, asignándoles una cuantificación libre, manteniendo el nivel de escalamiento base para las demás categorías de la correspondiente variable.
Las técnicas desarrolladas se ilustran a través del análisis de una población de pacientes con Cardiopatía Isquémica.
Estadística Genética y Pruebas Múltiples
Conferencista: Jorge Iván Vélez Valbuena, Msc. en Estadística
Fecha: Agosto 14 de 2009
Resumen
As advances in measurement systems as well as in data storage and generation become available, new challenges arise for statisticians in different fields. Genetics, imaging proces-sing and genomics, fields in which data sets with up to millions of variables by individual are measured, are just an example of this.
In this talk we will present few real-cases illustrating how the integration of biology, genetics, bioinformatics, statistics and statistical computing works and how we can take advantage of this to address specific research questions while working in a multidisciplinary research environment. Finally, some applications of statistical genetics and multiple testing using GNU software will be discussed.
Keywords: Statistical Genetics/Computing, Bioinformatics, Multiple Testing.
El Uso de Pruebas Aceleradas para Predecir la Confiabilidad de un Producto en el Mercado
Conferencista: Luis Alberto Escobar Restrepo, Ph.D
Fecha: Agosto 10 de 2009
Resumen
Accelerated Me tests (ALTs) provide timely assessments of the reliability of materials, components, and subsystems. ALTs can be run at any of these levéis or at the full-system level. Sometimes ALTs genérate múltiple failure modes. A frequently asked question near the end of an ALT program, is "What do these test results say about field performance?'1 ALTs are carefully controlled whereas the field environment is highly variable. Products in the field see, for example, different average use rates across the product population.
With good characterization of field use conditions, it may be possible to use ALT results to predict the failure time distribution in the field. When such information is not available but both life test data and field data (e.g., from warranty returns) are available, it may be possible to find a model to relate the two data sets. Under a reasonable set of practical assumptions, this model can then be used to predict the failure time distribution for a future component or product operating in the same use environment. This paper describes a model and methods for such situations. The methods wül be illustrated by an example to predict the failure time distribution of a newly designed product with two failure modes.
Búsqueda del Conocimiento y Estadística
Conferencista: Roberto Behar Gutiérrez, Ph.D
Fecha: Junio 1 de 2009
Resumen
Muchos libros de estadística que sirven de guía a los cursos básicos, traen una breve introducción y luego se desarrollan los temas específicos que corresponden un curso introductorio. En los últimos años, a raíz de mi interés por el tema de la educación estadística, he sentido la necesidad de incluir en todos los cursos un tema que permite contextualizar la metodología estadística sobre todo en los llamados cursos de servicio y está asociado con la relación de la estadística con aquello que se ha denominado "Método Científico", que intenta ser una guía para una buena búsqueda del conocimiento.
Además del efecto contextualizador, incluir este tópico, podría servir como un elemento de motivación en un curso, que no pocas veces, genera sentimientos y actitudes negativas de parte del estudiante.
En algunas ocasiones recibimos de los medios de comunicación o en publicaciones científicas o en las noticias, información aparentemente contradictoria sobre temas diversos. Cosas o hábitos que ayer eran consideradas patológicas por la ciencia, en nuevas publicaciones se plantean como inocuas o como virtuosas. Los ejemplos son abundantes.
Nos preguntamos: ¿Las investigaciones se hicieron mal? ¿Por qué estos bandazos? ¿Cómo confiar entonces en los resultados de la investigación científica, si esta no es segura?. ¿Cómo juzgar la validez de una investigación? ¿Qué tiene que ver la estadística en todo esto?. La charla programada reflexionará sobre estos asuntos.
Descargar pdf
Lógica Difusa, Conceptos y Aplicaciones en la Toma de Decisiones
Conferencista: Santiago Medina Hurtado, Ph.D
Fecha: Mayo 18 de 2009
Resumen
En las últimas cuatro décadas se ha experimentado un cambio importante en el tratamiento de la incertidumbre. Los desarrollos asociados a la teoría de conjuntos difusos han permitido levantar los paradigmas asociados a la teoría de conjuntos clásicos así como al uso de la teoría de probabilidades en el tratamiento de la incertidumbre. La lógica difusa ha permeado todos los campos del conocimiento desde las matemáticas básicas hasta la técnica. Esta conferencia muestra una aproximación al desarrollo de la lógica difusa y su aplicación a diferentes problemas asociados a la toma de decisiones.
Un Ejemplo de un Proceso Estocástico con Dependencia Alpha Mixing
Conferencista: Liliam Cardeño, Ph.D
Fecha: Mayo 11 de 2009
Resumen
Se considera un proceso estocástico estacionario tomando valores en un conjunto finito o enumerable. Dada un subsucesión de tamaño n, An, tomada de una realización de este proceso, se define la función 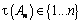 , como la posición de la primera sobreposición posible de An y con TAn denotando la primera ocurrencia de An , además se considera.
, como la posición de la primera sobreposición posible de An y con TAn denotando la primera ocurrencia de An , además se considera.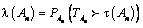
Siendo PAn la posibilidad condicionada a que An ya apareció. (Observe que 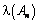 se puede interpretar como la probabilidad de “salir” de An. Hay resultados que muestran, bajo condiciones exigentes de dependencia, que existe
se puede interpretar como la probabilidad de “salir” de An. Hay resultados que muestran, bajo condiciones exigentes de dependencia, que existe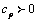 (que sólo depende de la medida de probabilidad p) tal que
(que sólo depende de la medida de probabilidad p) tal que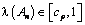
Contrario a esta situación, se construye una familia de procesos (con dependencia “más débil”) que contiene una sucesión 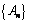 , con n en los naturales, tal que
, con n en los naturales, tal que 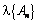 va para 0 cuando
va para 0 cuando 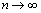 .
.
Se espera hacer una presentación de nivel introductoria dirigida a estudiantes con conocimientos en probabilidad básica.
Equilibrio Inter-Temporal con Utilidades Dependientes de Estado
Conferencista: Jaime Alberto Londoño Londoño
Fecha: Abril 27 de 2009
Resumen
Se da una caracterización simple de equilibrio inter-temporal para mercados (financieros) completos cuando los agentes maximizan un funcional dependiente de estados (Londoño J.A. State Dependent Utility J. Appl. Prob. 46(1): 55-70 ). Adicionalmente se presenta como estos mercados son consistentes con no-arbitraje. La caracterización dada puede ser usada para determinar caso por caso cuando el modelo propuesto es en efecto completo. Los desarrollos teóricos usados son una generalización a mercados financieros cuando los procesos son Fluidos Brownianos definidos en Variedades. Se ilustra la construcción de los
mercados propuestos por medio de un ejemplo.
Órdenes de Experimentación en Diseños Factoriales
Conferencista: Alexander A. Correa Espinal, Ph.D
Fecha: Abril 13 de 2009
Resumen
Cuando se plantea un diseño factorial la práctica habitual es recomendar que los experimentos se realicen en orden aleatorio. Esta aleatorización tiene como objetivo el proteger de la posible influencia de factores desconocidos, ya que se espera que esa influencia quede difuminada entre todos los efectos de forma que ninguno se vea especialmente afectado y no se cometan errores al valorar su significación estadística.
Pero este proceder tiene dos inconvenientes importantes: El número de cambios de nivel en los factores que exige la aleatorización puede ser grande (bastante mayor que otras posibles ordenaciones) y difícil de llevar a la práctica, lo que complica y encarece la experimentación. Y si se realizan unas hipótesis que parecen muy razonables respecto al tipo de influencia que ejercen los factores desconocidos, existen órdenes claramente mejores que otros para minimizar la influencia de esos factores ajenos a la experimentación.
Individualización de la Dosis de un Medicamento Mediante el Uso de un Modelo Lineal con Intercepto Aleatorio
Conferencista: Francisco Javier Díaz Ceballos, Ph.D
Fecha: Marzo 30 e 2009
Resumen
Un problema de gran interés en farmacología clínica es la determinación de la dosis individualizada óptima de un medicamento, con el fin de producir una concentración deseada del medicamento en el suero del paciente, o de producir una concentración que esté dentro de un intervalo de concentraciones deseado. Este problema se presenta en la práctica clínica, cuando el clínico quiere que la concentración del medicamento en el suero de un paciente caiga dentro de una ventana terapéutica que incluya concentraciones efectivas y no tóxicas. El propósito de esta presentación, es describir una propuesta de un procedimiento clínico para la individualización de la dosis de un medicamento en un paciente (Diaz et al. 2007, Statistics in Medicine 26, 2052-2073).
El procedimiento asume que el logaritmo de la razón concentración/dosis del medicamento en el estado estable puede modelarse mediante un modelo de regresión lineal con intercepto aleatorio. El procedimiento clínico es esencialmente un algoritmo adaptativo que tiene como objetivo el estimar el valor del intercepto que es específico del paciente. En cada paso del algoritmo, se re-predice el intercepto aleatorio a través de un enfoque de teoría de la decisión que está basado en una función de pérdida que surge de manera natural en un contexto de individualización de la dosis de un medicamento.
Se calcula el mínimo número de pasos del algoritmo que son necesarios para encontrar la dosis óptima. Los cálculos se ilustran con el medicamento clozapina, el cual es un antipsicótico usado para tratar pacientes con esquizofrenia. Finalmente, se discute la factibilidad del modelo, y se habla brevemente de la robustez del modelo en caso de que existan covariables con efectos aleatorios.
Funciones de Cuasi-Probabilidad: Una Herramienta útil en la Mecánica Cuántica
Conferencista: Herbert Vinck Posada, Ph.D
Fecha: Marzo 16 de 2009
Resumen
El desarrollo de la mecánica cuántica durante el siglo XX ha dotado a la física de nociones y conceptos realmente novedosos que día a día afianzan más sus posibilidades predictivas y la manera de buscar en éstas, posibles desarrollos tecnológicos. En particular, las áreas donde más se ha trabajado con resultados sorprendentes son: la óptica cuántica y los sistemas mesoscópicos, en los que entre otras cosas, se tratan los estados cuánticos de la luz.
En esta charla, se presentarán las conocidas funciones de cuasi-probabilidad y su aplicación en éstas áreas de investigación. Cabe resaltar que mediante estas funciones de cuasi-probabilidad es posible plantear criterios para la diferenciación entre un sistema clásico y uno mecánico cuántico
Diseños óptimos en el Escenario de Múltiples Objetivos
Conferencista: Victor Ignacio López Ríos, Ph.D
Fecha: Marzo 2 de 2009
Resumen
La teoría de los diseños óptimos, como uno de sus objetivos, proporciona las condiciones óptimas donde se debe realizar un experimento con el fin de satisfacer algún criterio de optimalidad, funcional de la matriz de información. En este trabajo se aborda un problema de farmacocinética donde el interés está en encontrar tiempos de muestreo óptimos que permitan estimar varias funciones no lineales como: el área bajo la curva, el tiempo para la concentración máxima, y la concentración máxima, además de tener una buena potencia para discriminar entre dos posibles modelos candidatos. Se hallarán diseños óptimos locales y diseños óptimos bayesianos. Se harán comparaciones entre ellos a partir de las eficiencias de cada uno de los diseños obtenidos.